以前给教研人员培训时,常会提到要用Approaches and Methods in Language Teaching这本书里提供的一个模型来科学地分析各种语言教学方法。
而我在十多年教学的过程中,结合我自己学习英语的经验,不知不觉总结出了“泛精结合、查听仿生”的语言能力训练方法。
但我一直都没有拿这个模型给自己的这套说辞进行过严谨的分析,那就通过这篇文章做一次尝试吧。
接下来就用前面提到的那个模型来分析一下我所谓的“泛精结合、查听仿生”这个方法。
如果不够严谨,正好也可以借此机会完善一下。
一、分析模型
科学地分析一个语言教学理论或者方法的模型如下图:
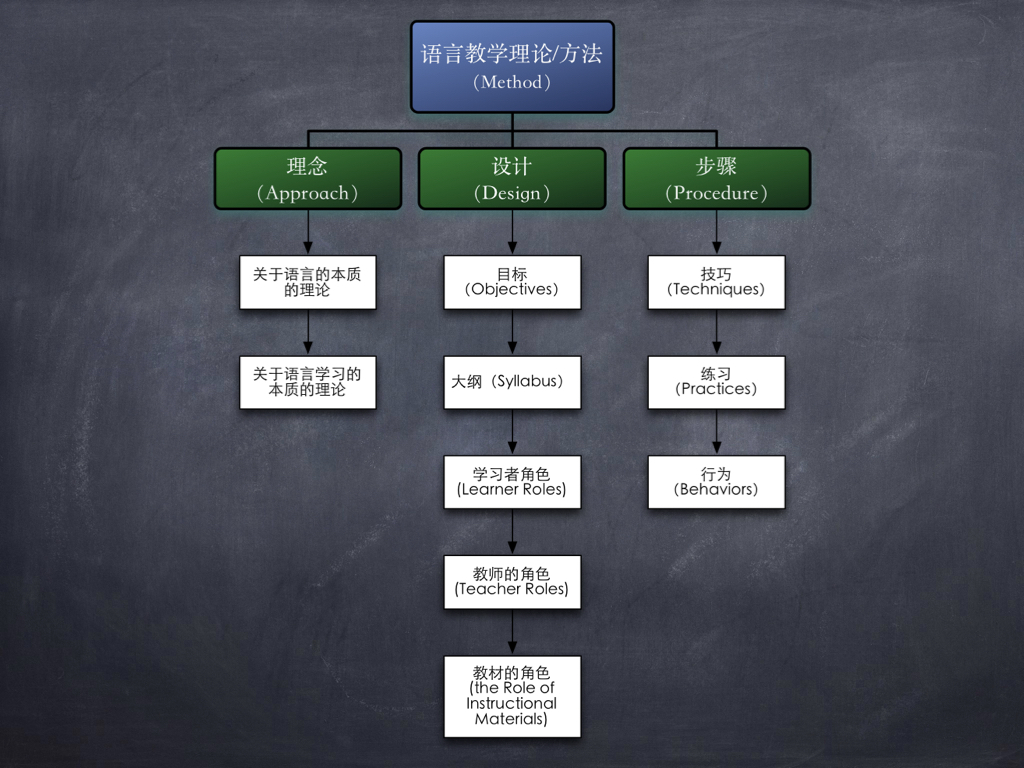
二、理念
2.1 关于语言的本质的理论
语言是传递信息的途径之一,其通过人体多感官的联动以声音、表情、肢体语言为主要展现形式传递说话者想要表达的意象。
2.2 关于语言学习的本质的理论
获得语言能力的过程是建立信息与多感官协作的关联的过程,在这些直接关联的基础上,学习者将会获得生成性输出的能力。
三、设计
3.1 目标:
让初学者在没有目标语言环境的条件下,仍然能建立起语言与人类本身的语言运用能力的关联,通过大量跟声音的直接互动,让学习者建立声音与其所传递的准确意象跟发声器官的运作、所有感官的感受、内心的情感之间的直接关联,以便在输出时能条件反射似地调动所有相关的器官、感官和情感以最直接、自然的方式表达想要表达的意象。
主要适用于初学者建立中级阶段以前的语言运用能力(CEFR的A1到B2阶段),在更高级阶段中仍可继续保持该训练习惯,并辅以其它必要的方法以获得更多高级阶段的语言运用能力。
3.2 大纲:
目前并没有固定的训练素材。原则上讲,任何至少带有母语人士录音的素材都可以采用。如果有视频、图片等资料则更佳。
而素材的组织方式需要灵活考虑不同人群、不同需求进行特别设计。因此未来应当会有基于该方法的各种不同课程内容与形式,而不仅仅采用一套大纲以期解决所有人的需求。
3.3 学习者角色:
学习者主要是训练的参与者。通过跟声音直接互动,进行长期的、高标准的训练,持续建立语言跟自身多个感官之间的联动,以获得生成性输出的能力。
3.4 教师的角色:
教师主要是教练的角色。引导学习者进行训练,在训练中提供关于训练情况的即时反馈以便学习者的训练更高效,同时提供心理上的支持以便学习者更容易保持持续的训练。
3.5 教材的角色:
根据不同人群、不同需求提供实用的训练素材,至少有文字与相匹配的录音,其它媒体形式越多越好,以便辅助学习者建立更多感官的关联。
四、步骤 技巧、练习与行为:
为了更有效地建立关联,可以把训练过程分为泛学和精学两类:
4.1 泛学:
用于提升学习广度(占总学习时间的70% – 80%)
学习过程中忽略细节,在可理解的前提下大量输入即可。主要目的是建立大量的视觉、听觉与所传递的信息之间的关联。
4.2 精学:
用于提升学习深度(占总学习时间的20% – 30%)
具体的做法就是用“查、听、仿、生”四个步骤进行精细化练习。在这个步骤里一定要追求精益求精,练习的内容不能多,但要以最高标准进行训练。
4.2.1 查——准确理解
这一步是一切的基础,也是最容易被忽略的一步。在开始练习之前一定要认真查词典,搞清楚要练习的内容究竟在讲什么,每个词都要弄明白。这里最常见的陷阱就是那些自认为认识的单词,所以如果只查自认为的生词的话是远远不够的,把握一个原则,只要有一丝模糊就马上查词典,一定做到100%明确,最好是每个单词都查,这样就很难有遗漏了。
除了查词外,有必要的情况下还需要查相关的语法点、文化背景知识、相关联的其它资讯等等。总之要做到既充分理解字面意思,又理解文字背后的意思,以便后续的训练中与准确的意象建立关联。
4.2.2 听——客观听音
所谓客观就是指不要被曾经习惯的发音所干扰,忘掉以前,听到什么就是什么,不论是不是符合过去的记忆。在听的过程中可以使用一些符号进行标注来辅助听音,但不用学习音标,只要自己明白是什么意思,任何符号都可以。
4.2.3 仿——客观模仿
当能把所有的发音细节听清楚以后,就可以开始张嘴跟读练习了,但也要注意客观两个字。主要体现在那些不符合个人发音习惯或者记忆中的语音知识的地方,要忘掉一切,客观地按照所听到的声音去模仿,把不习惯的发音练成新的习惯。
模仿时除了模仿语音语调之外,更重要的是要找到自己在说话的感觉。第一步的作用就在这里体现出来了,只有清楚地知道自己在说什么的时候,才能更准确地找到自然地说话的感觉。
模仿可以分两个阶段:
- 异步模仿:以一个意群为单位播放一遍原声,跟读一遍,跟读时语速先尽可能慢,随着熟练度提升逐渐加快速度直到跟原声速度一样;
- 同步模仿:熟练度达到跟原声语速一样时则可以在播放该片段时与原声同时发声,关注原声的节奏与语调变化,类似唱卡拉OK一样,练到跟原声的节奏与语调完全一致为止。
4.2.4 生——生成性输出
生成性输出可以从两个方面来理解:
- 在查、听、仿三个步骤完全做到位,把声音跟意象以及自己的发声器官的运作建立顺畅的关联之后,想像真实的语言情景,像一个演技高超的演员一样,真实地说出来,而不是毫无情感地读句子;
- 生成性输出同时也是一个自然产生的结果,前三个步骤所建立的直接关联不是靠逻辑思考实现的,人类与生俱来的语言习得机制会让语言学习者在与目标语言大量直接接触的过程中自然获得语言能力。其结果并不仅仅是能让学习者能应用曾练习过的表达,更重要的是可以自然地进行生成性输出。也就是说在已有的能力基础上自动按照语言的规律产生新的表达。
以上通过这个模型把这套训练方法比较全面地进行了分析和梳理。随着今后教学的实践,我还会不断进行完善。尤其是大纲部分是主要缺失的环节,这也将是今后发展中需要大量实践积累与总结的部分。

 我想稍微整理一下,我把之前我的删掉一些吧。
我想稍微整理一下,我把之前我的删掉一些吧。